3月1日晚間,微盟發佈公告,稱在合作方騰訊雲的協助下,數據已經全面找回,預計於2020年3月3日上午9點完成數據恢復上線。
騰訊雲官方微博也發布消息,表示數據恢復的複雜度超出所有人想像,“連續通宵、排除萬難,終於攻堅成功!”
不過,數據雖然恢復了,損失依舊慘烈。
事故發生在2月23日晚上,微盟公司的SaaS業務突然崩潰,基於微盟的商家小程序都處於宕機狀態,300萬家商戶生意基本停擺。
而造成此次嚴重事故的,竟然是微盟的一名員工——憑一己之力,刪除自家公司數據庫,累計市值蒸發超30億港元。
針對事故給商家造成的影響,微盟表示:
管理層深感自責和愧疚,準備了1.5億元人民幣賠付撥備金,其中公司承擔1億元,管理層承擔5000萬元。
經過這樣“段子”一樣的事件,也給企業敲響了一個警鐘——“數據安全大於天”。
賠付1.5億元,決定全面雲上
今天,微盟在其官方網站上發布了自願公告《SaaS業務生產環境和數據恢復》,描述此次事故及修復過程,以及賠付方案和數據安全保障計劃。
本次事故及修復過程
2020年2月23日,因本公司員工故意破壞本公司SaaS 業務生產環境及數據,導致本公司暫時無法向客戶提供SaaS 產品,目前該員工已被上海市公安局寶山分局刑事拘留。
2020年2月25日,本公司恢復了核心SaaS 業務的生產環境,SaaS 業務新用戶可繼續使用本公司的SaaS 產品,本公司也向老用戶提供臨時過渡方案,確保商家在數據恢復前可繼續經營。
2020年2月28日,本公司恢復了所有SaaS 業務的生產環境,並且開放了老用戶登錄,以及恢復了微站產品的所有備份數據。
截至2020年3月1日晚8 點,在騰訊雲的協助下,本公司備份的數據已經找回。由於此次數據量規模龐大,為了保證數據一致性和線上體驗,本公司將於2020年3月2日凌晨2點至上午8點,進行數據恢復上線演練,在此期間本公司的系統將會暫停服務,演練完成後系統數據會回滾到2020年3月2日的數據。
本公司將於2020年3月2晚上10點至2020年3月3日上午9 點,正式進行數據恢復上線。本公司將恢復2020年2月23日及之前的數據,同時將2020年2月23日與2020年3月2日的數據進行合併,屆時數據恢復將完成。
針對本次事故的賠付方案
鑑於本次事故給本公司的SaaS業務商家經營造成了不利影響及損失,本公司管理層在緊抓資料恢復的同時,也同步研究了商家賠付方案。
針對本次事故可能帶來的潛在現金賠付和流量賠付,本公司和本公司管理層合計準備了人民幣1.5 億元的賠付資金,其中人民幣1 億元由本公司承擔,人民幣5,000 萬元由本公司管理層承擔,具體進行賠付時本公司和上述本公司管理層將在上述披露的限額內將按比例做出支付。
數據安全計劃
本次事故雖由員工的不當行為引起,但也暴露出本公司在數據安全管理方面的不足之處。
為此,本公司已邀請外部數據安全專家協助本公司製定和評估數據安全保障計畫,主要覆蓋生產環境和數據權限的分級管理和執行、將數據移轉到騰訊雲數據庫、加強意外事件快速應對能力以及運維人員的法律和職業道德學習等方面。
本公司正在逐步落實上述數據安全保障措施,以避免此類事故的再次發生。
七天七夜,為何恢復數據如此漫長?
其實,我們也經歷過許多常用軟件崩潰的情況,例如去年12月5日,支付寶網絡出現抖動,12月26日微信公眾號崩潰,但是騰訊和阿里的恢復時間還是比較迅速,分別只用了25分鐘和45分鐘。
而微盟此次數據庫被刪,在騰訊雲的協作下,為何還要耗時7天7夜之久?
對此,業界知名實戰派軟件質量和研發工程效能專家茹炳晟,發表了一些看法,主要原因歸結於技術過於復雜。
首先需要了解的是數據庫的運行環境,簡化來講,主要包括三種:“不上雲”、“全上雲”和“假上雲”。

“不上雲”是指建立在自己的數據中心,完全自己管理硬件、軟件和數據,這是雲平台普及以前的主流實踐。
“全上雲”是指完全建立在雲端環境之上。這裡的雲可以是公有云,也可以是私有云。
“假上雲”是把雲方案當做虛擬機來使用。這種方式和上面的“不上雲”很類似,完全沒有用好雲端的優勢,只是把數據中心的機器移到了雲端而已。
對於上面三種方式,“不上雲”和“假上雲”對於數據的風險相比“全上雲”會更大。
運維人員在“不上雲”和“假上雲”的情況下更容易有機會去執行類似“rm -rf /*”和“fdisk”類型的極端操作。
而“全上雲”,就比較難有機會從操作系統層面執行此類命令,數據庫數據也就不會被rm -rf /給刪掉。
同樣,面對數據的誤操作問題,“全上雲”也比“不上雲”和“假上雲”有明顯的優勢。
從之前騰訊雲對外的回應中,可以大概看到微盟被刪的數據不在騰訊雲上,再結合目前數據恢復的速度來看,幾乎可以判定很大概率微盟沒有採用“全上雲”的架構,或者是只有部分數據在雲端。
要在這種情況下恢復全部數據,可想而知技術難度是很大的。
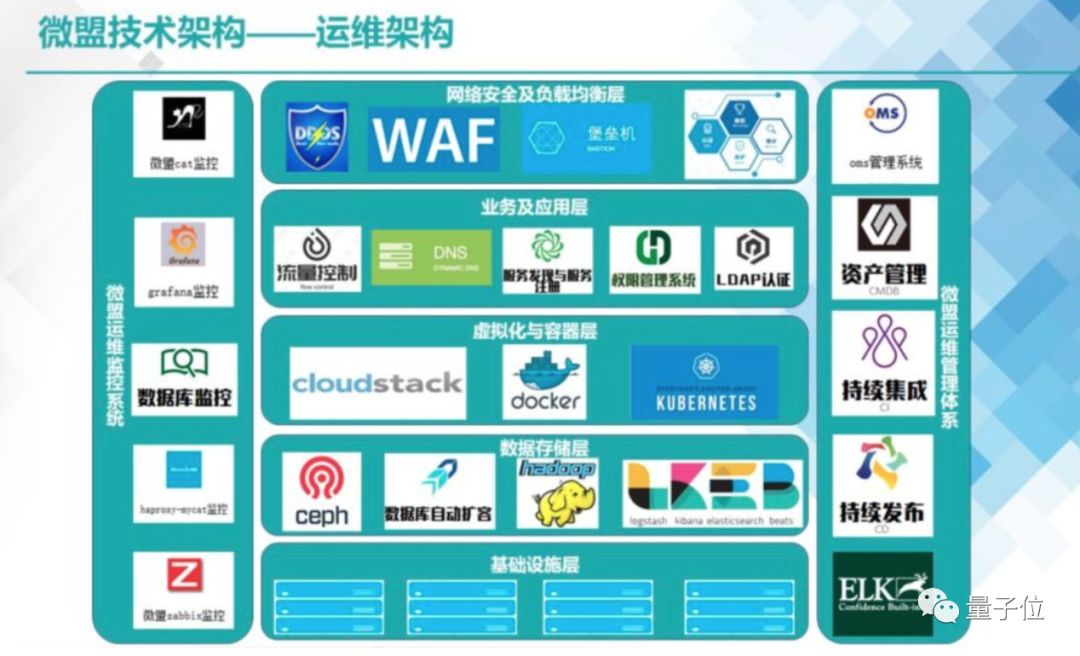 △圖源:微盟技術中心
△圖源:微盟技術中心
根據茹炳晟的理解,至少要跨過下面這些技術的檻:
⑴獲取全量備份,如果存在異地的冷備或者災備,那是比較理想的情況,但是由於全量備份通常非常龐大,所以需要較長的時間完成文件的傳輸和校驗。
⑵獲取增量備份,很多時候增量備份沒有來得及做異地容災備份,所以很大概率要從磁盤恢復,這又是大量的時間消耗,而且同樣不能保證100%完全恢復。
⑶獲取binlog,binlog是記錄所有數據庫表結構變更(例如CREATE、ALTER TABLE等)以及表數據修改(INSERT、UPDATE、DELETT等)的二進制日誌文件。文件尺寸不小,而且個數也很多。
有了上面這些作為基本的輸入,才能開始數據庫層面的數據導入和恢復工作,這個過程也需要花費大量的時間,而且這是基於上述文件都可以100%得到為前提的。
數據庫的數據文件和備份文件往往很大,那麼只要有個別數據區出現了重寫,那麼恢復出來的文件就是不完整的,這個時候就需要人為介入來進行修正,這個工作量以及技術難度就會很大,有時還會需要藉助專用的儀器設備。
除此之外,像微盟如此龐大的系統,各個垂直事業部可能都有各自的業務數據庫,這些數據庫甚至可能採用了不同的方案,這種架構上的異構性也會給恢復過程帶來極大的挑戰。
另外,即使部分數據恢復完成之後,也不能立即上線,而要等其他相關數據恢復,並且做好數據的交叉校驗,確保數據萬無一失,這些都需要大量的時間。
聯想數據恢復中心專家趙臻也認為,數據量規模過大,是數據恢復實施難點之一。
由於技術方案相對成熟,人工效率不是瓶頸,通過計算硬盤I/O速度,可以大致評估出整個恢復過程的時效。但是數據量規模過大會導致容錯率降低,每一次人為原因或設備原因導致的錯誤都會增加很多額外的恢復時間。
同時數據量規模過大還會導致恢復所需資源的增加,對整個恢復的成本造成很大的影響。
數據安全大於天
經此一役,也讓我們認識到了數據安全的重要性,如何預防這種數據丟失的情況,也開始被更多人討論。
有一些過來人高讚建議:
公眾號“成哥的世界”建議,企業可以使用雲數據庫產品,因為公有云廠商具有相對比較完善的自動備份和恢復機制,沒有機會被刪庫;做好備份,做好全量備份、增量備份、延遲備份,而且要多機房異地備份;管理好控制權限,用主機安全管控軟件或者堡壘機來攔截高危命令;進行普法宣傳,給予警示告誡,防止相關人員想不開。
而知乎用戶“空白白白白”則建議,企業應當建立敏感數據操作雙人復核機制,需要雙人審批;用異地災備或異步通訊的方式做數據實時備份;建立關鍵應用業務的刪庫監控機制,做重要操作的時候需要確認。
而從茹炳晟對此次數據恢復技術難點的分析中,也可以看出“全上雲”具有相對的安全性。
但同時,也有讀者留言反饋道:
作為雲管理者,全上雲的數據還是能刪光的。任何云都有初始化手段,全上雲就是把安全交給別人。

那麼問題來了,對於“全上雲” or “Not 全上雲”,你怎麼看?
沒有留言:
張貼留言